
Mit SharePoint Syntex werden unstrukturierte Informationen automatisch verarbeitet und in nutzbares Wissen umgewandelt. Die künstliche Intelligenz (KI) hält Einzug in den Büroalltag und kann nun «angefasst» und genutzt werden. Syntex ist ein Add-On von SharePoint und kann weltweit genutzt werden. Syntex bietet zwei Modelle für die Verarbeitung von Informationen.
Was ist SharePoint Syntex?
Syntex ist ein intelligenter Inhaltsdienst (Content Service), welcher künstliche Intelligenz (KI) und Machine Teaching nutzt. Syntex kann nach einem kurzen Training der AI-Modelle Dokumente/Scans/Fotos auf SharePoint selbstständig analysieren, Metadaten anreichern und die Inhalte klassifizieren. Aus Inhalten wird nutzbares, strukturiertes und indexiertes Wissen. SharePoint Syntex hat wie ein digitaler Arbeitskollege oder eine digitale Arbeitskollegin den Task der Analyse und Klassifizierung übernommen.

Machine Teaching heisst, dass die Maschine trainiert und angelernt werden muss, bevor die Aktionen wie gewünscht durch KI vorgenommen werden.
SharePoint Syntex nutzt bereits implementierte SharePoint Services und andere M365-Tools. So werden die zentralen Inhaltsservices Termstore, für Tenant-weite Metadaten, wie auch Inhaltstypen in Syntex genutzt. Als M365-Tools kommen Power Automate, für die Automatisierung von bspw. nachgelagerten Prozessen und auch das Security & Compliance Center, für das automatische Kennzeichen der Dokumente oder die Aufbewahrung, zum Einsatz.
Wir müssen die Maschinen nicht mehr programmieren, wir werden sie trainieren.
Marc Holitscher, National Technology Officer und Mitglied der Geschäftsleitung von Microsoft Schweiz
Auszug aus dem Gastinterview mit Marc Holitscher in unserem kostenlosen E-Book «Microsoft Teams Excellence»
Welche Funktionen bietet Syntex?
SharePoint Syntex bietet eine Vielzahl von Funktionalitäten, diese können teilweise einzeln oder in Kombination genutzt werden:
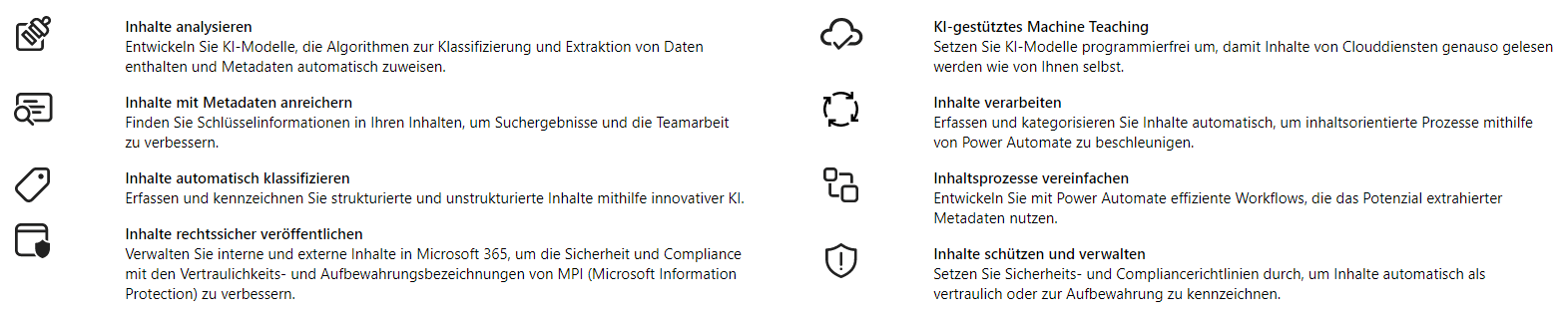
Die Funktionen von SharePoint Syntex können dabei in folgende Kategorien unterteilt werden:
- Inhalte analysieren (Entwickeln von KI-Modellen)
- Wissen intelligent erfassen (Machine Teaching – das «Anlernen» des KI-Algorithmus‘)
- Inhalte mit Metadaten anreichern
- Inhalte verarbeiten (Inhaltsorientierte Prozesse beschleunigen)
- Inhalte automatisch klassifizieren
- Inhaltsprozesse vereinfachen (mit Power Automate Daten weiterverarbeiten)
- Rechtssichere Inhalte veröffentlichen (Einhaltung gesetzlicher Vorschriften verbessern)
- Inhalte systemübergreifend verbinden
- Inhalte schützen und verwalten
Welche KI-Modelle stehen in Syntex zur Verfügung?
Für die Verarbeitung der Informationen stehen zwei Modelle zur Verfügung:
- Form processing model
- Document understanding model
| Form processing model Formularverarbeitungsmodell | Document understanding model Dokumentverständnismodell |
|---|---|
| Strukturierte wie auch teilstrukturierte Daten bspw. Formulare | Unstrukturierte Daten bspw. Briefe, Verträge |
| Erstellt aus der Dokumentbibliothek | Erstellung und Verwaltung im Syntex Inhaltscenter |
| Auf eine einzelne Bibliothek beschränkt | Kann auf mehrere Bibliotheken angewendet werden |
| Verarbeiten digitaler Inhalte – Fotos, Scans, Quittungen, Visitenkarten, Videos mit OCR & Text | Erfassen von Inhaltstypen und Metadaten aus unstrukturierten Dokumenten |
| PDF-, JPG-, PNG-Format | PDF-, Office- oder E-Mail-Dateien |
Die vorliegende Productivity News bezieht sich auf das Document unterdstanding model.
SharePoint Syntex in 6 Schritten aktivieren und anwenden
Um mit Syntex zu starten, muss ein Syntex Inhaltscenter erstellt werden, im Inhaltscenter können dann Beispieldateien hochgeladen und die Modelle angelegt, konfiguriert, mit den Daten trainiert, auf Bibliotheken angewendet und ausgewertet werden. Aber alles der Reihe nach…
Schritt 1: Inhaltscenter erstellen
Das Setup für das Syntex-Inhaltscenter wird, nach erfolgter Lizenzaktivierung, im Microsoft 365 Admin Center vorgenommen. Danach kann die entsprechende SharePoint Site aufgerufen werden, in welcher die benötigten Funktionen bereitgestellt werden sollen. Falls mehrere Syntex Inhaltscenter erstellt werden sollen, können diese im SharePoint Admin Center angelegt werden. Dafür ist eine neue Site mit dem entsprechenden Template zu erstellen.
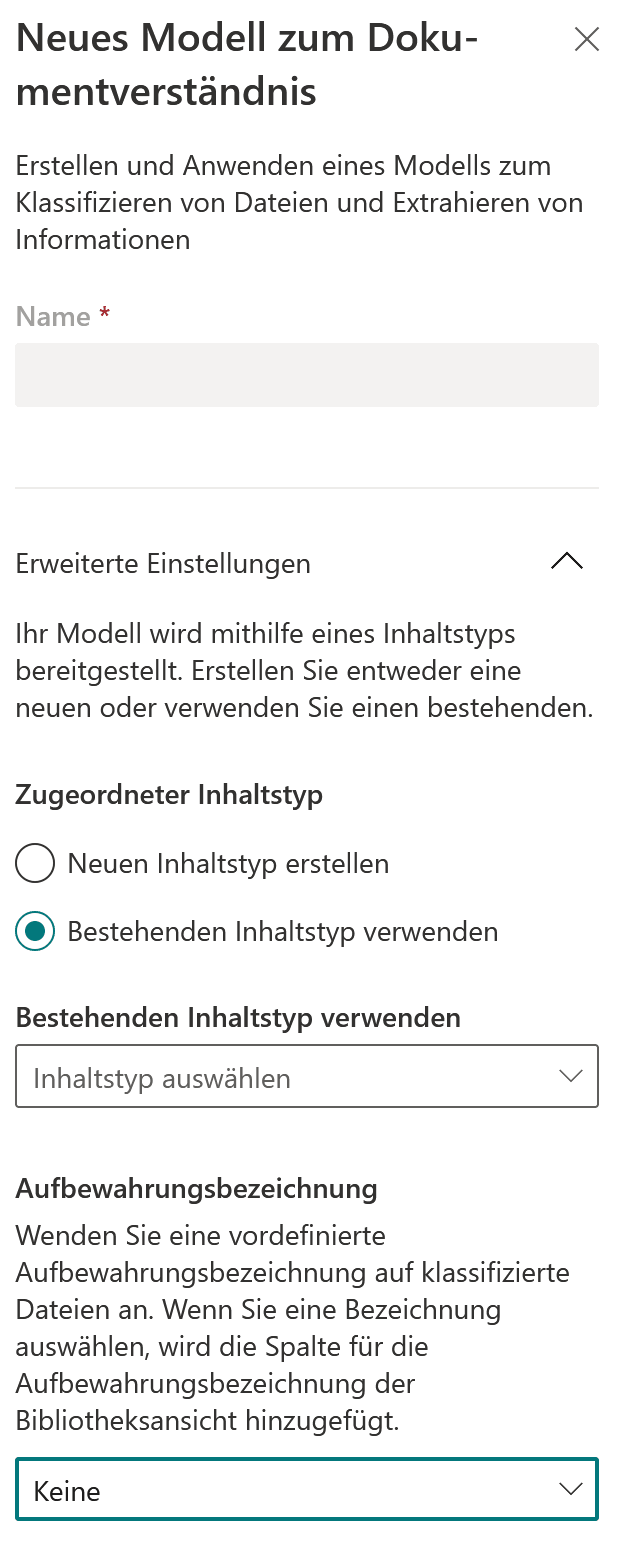
Schritt 2: Modell erstellen
Im Inhaltscenter muss danach ein neues Modell angelegt werden. Dabei kann direkt ein neuer Inhaltstyp erstellt oder ein bestehender Inhaltstyp verwendet werden. Zudem kann eine vordefinierte Aufbewahrungsrichtline für den Inhaltstyp ausgewählt werden.
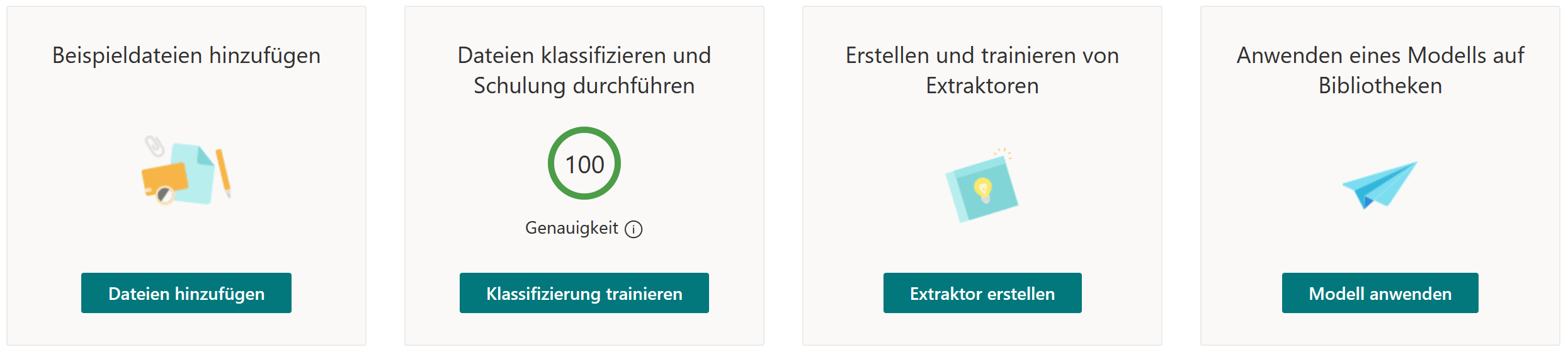
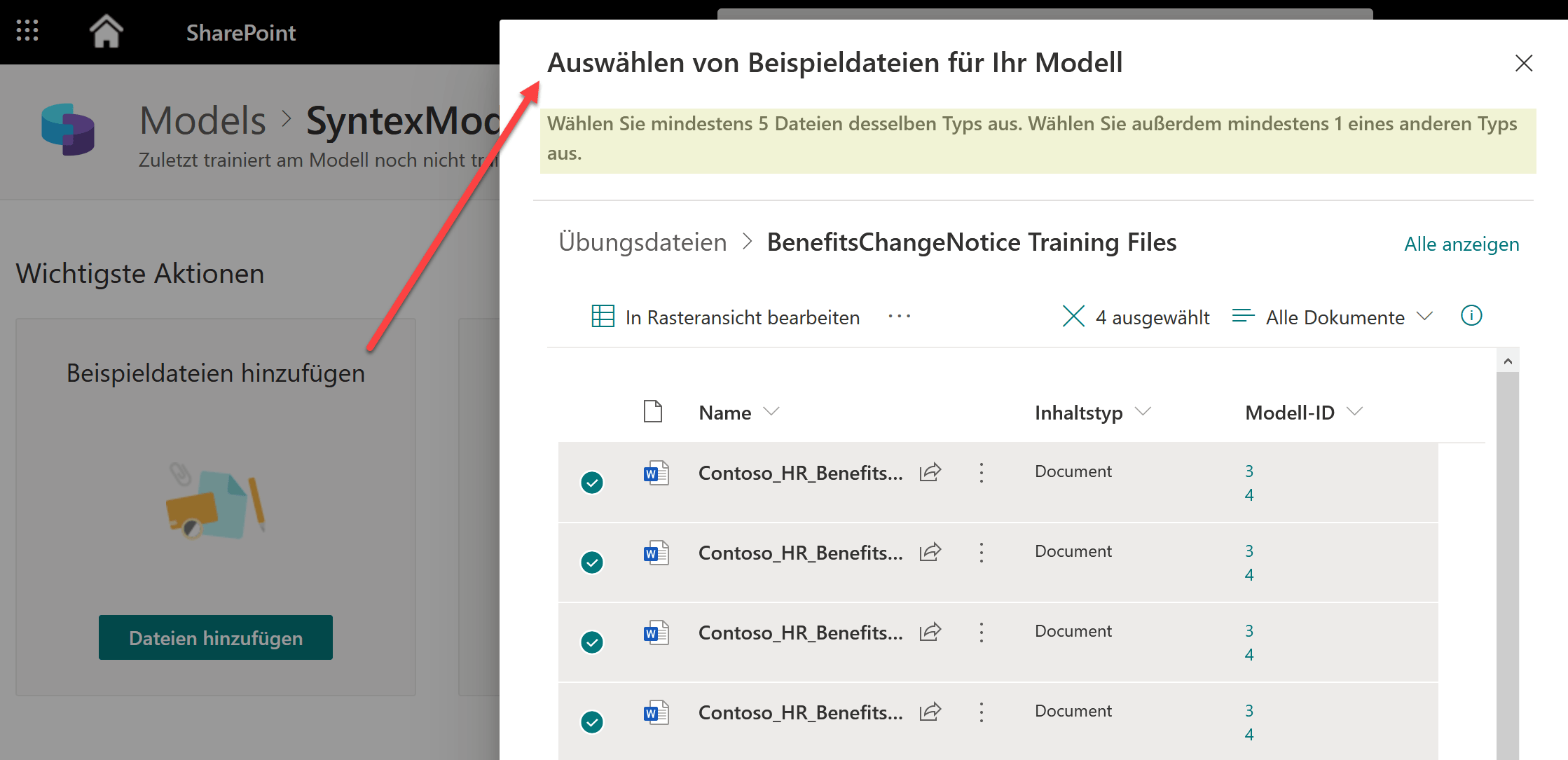
Schritt 3: Beispieldateien hinzufügen
Um Syntex zu trainieren, müssen Beispieldateien hinzugefügt werden. Dabei müssen mindestens 5 «positive» Dateien, also solche die unserem zu trainierenden Muster entsprechen, und mindestens 1 «negatives» Muster, also eine Datei, die NICHT dem gewünschten Muster entspricht, hochgeladen werden.
Schritt 4: Dateien klassifizieren und Training starten
Die hinzugefügten Daten müssen nun klassifiziert und Syntex trainiert werden. Als erstes müssen die «positiven» wie auch die «negativen» Dateien bezeichnet werden, so erfährt Syntex, welche Dateien unserem gewünschten Muster entsprechen.
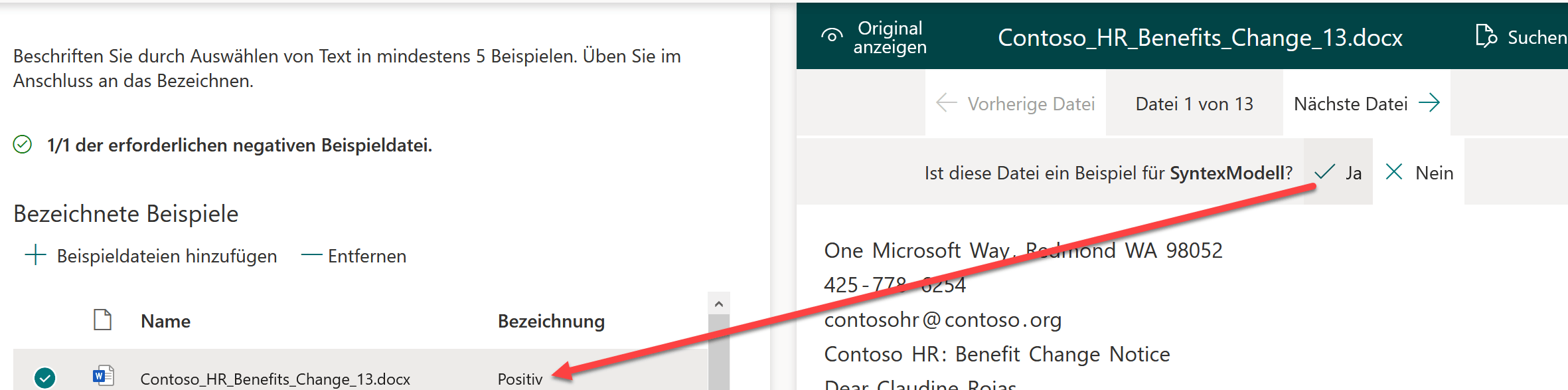
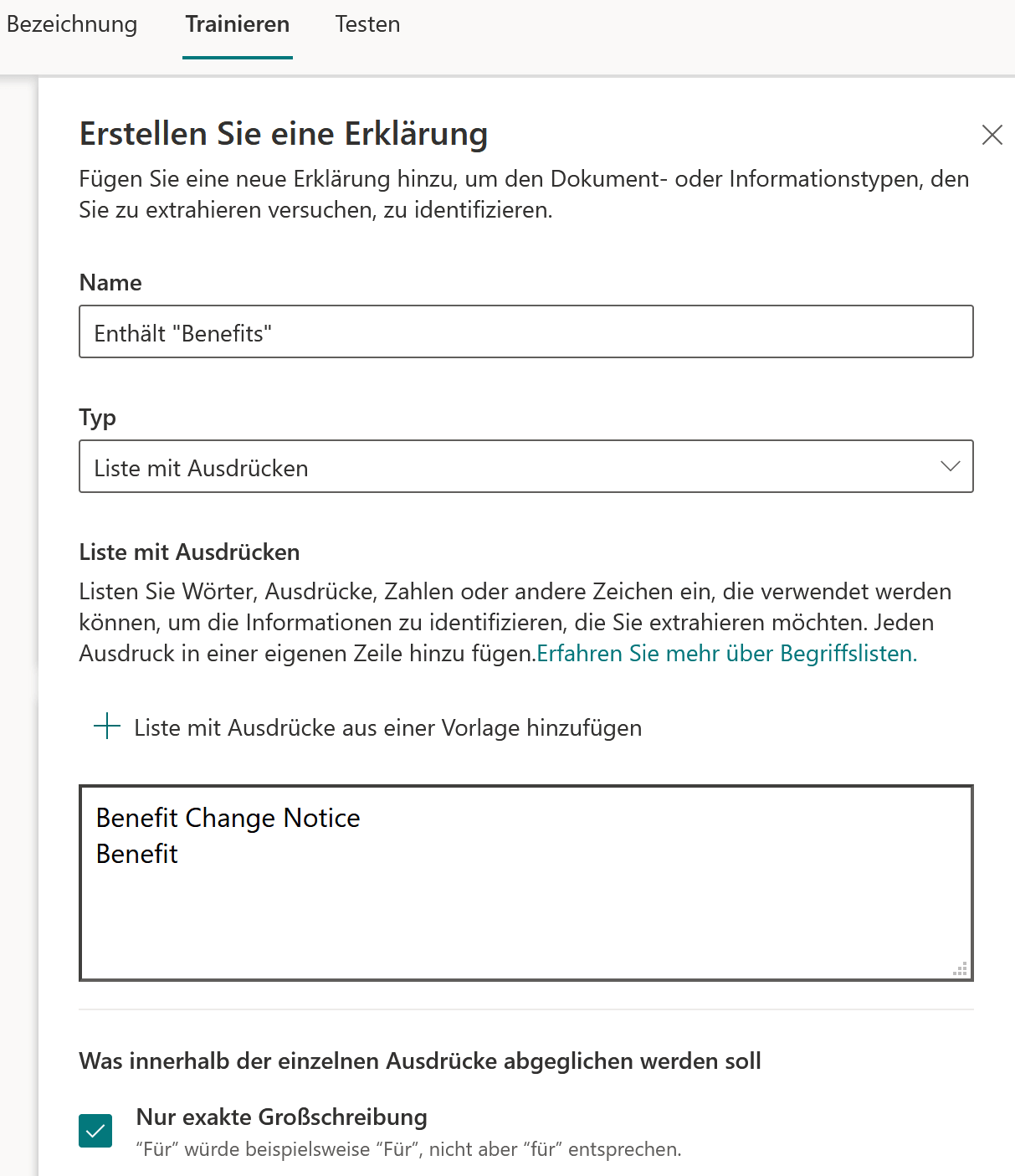
Danach werden aufgrund von Begriffen die gewünschten Dateimuster identifiziert und so die Dateien automatisch klassifiziert. Im Beispiel werden Dokumenten klassifiziert, wenn die Begriffe «Benefit Change Notice» oder «Benefit» darin vorkommen.
Nach dem Speichern der Begriffsdefinition arbeitet Syntex alle Beispieldateien durch und die Genauigkeit (oben rechts) wird mittels eines Prozentsatzes ausgegeben. Im Beispiel konnten die Beispieldateien zu 100% korrekt identifiziert und klassifiziert werden 🙂 .
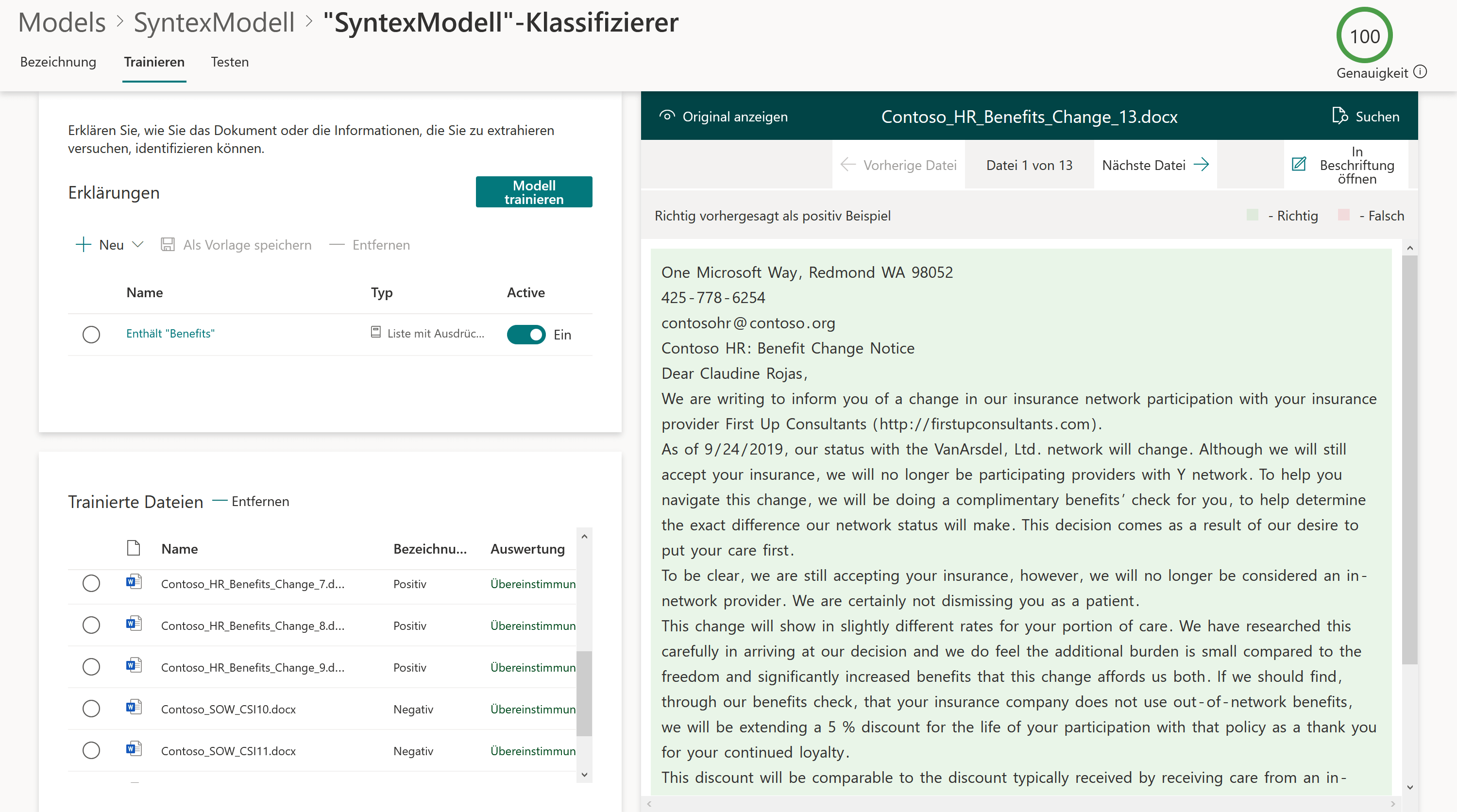
Mit den Schritten bis hierhin können die Dokumente klassifiziert und bei Bedarf an geeignete Speicherorte verschoben werden. Das erstellte Modell kann nun auf Bibliotheken angewendet werden (siehe Schritt 6: Modell auf Bibliothek anwenden). Falls aber noch Daten aus den Dokumenten extrahiert werden sollen, dann gehts mit dem nächsten Schritt weiter.
Schritt 5: Extraktoren erstellen und trainieren
Mittels «Extraktor erstellen» wird eine neue Spalte angelegt oder es kann eine bestehende Spalte ausgewählt werden, in der danach die extrahierten Daten aus den Dokumenten geschrieben werden.
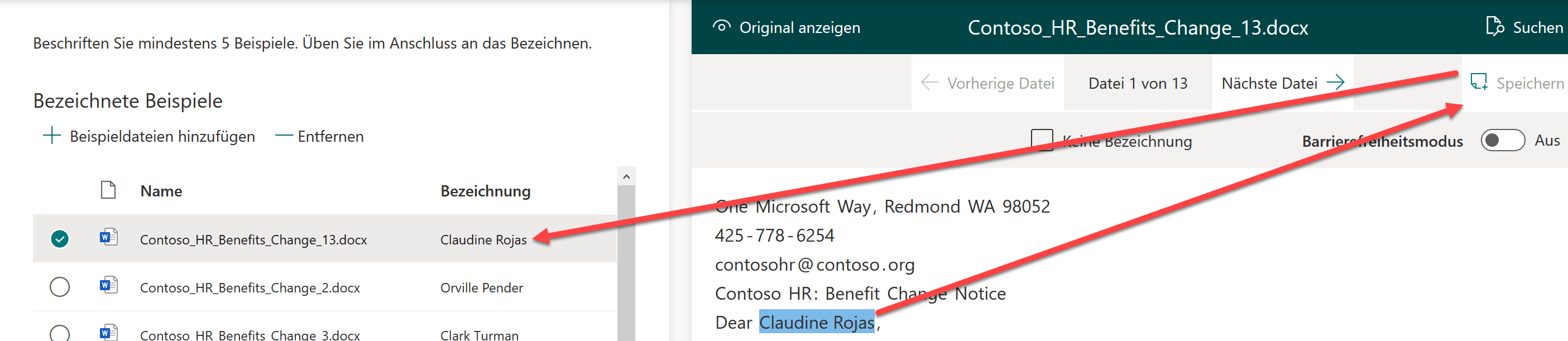
Im nächsten Schritt werden die Bezeichnung für Syntex definiert. Dabei wird in den «positiven» Dokumenten jener Wert markiert, der in ein Feld übernommen werden soll. Nach dem Markieren und Speichern wir der Wert dann übernommen. Dieser Vorgang wird für alle Dokumente durchgeführt, bei den «negativen» Dokumenten muss dann jedoch «Keine Bezeichnung» definiert werden.
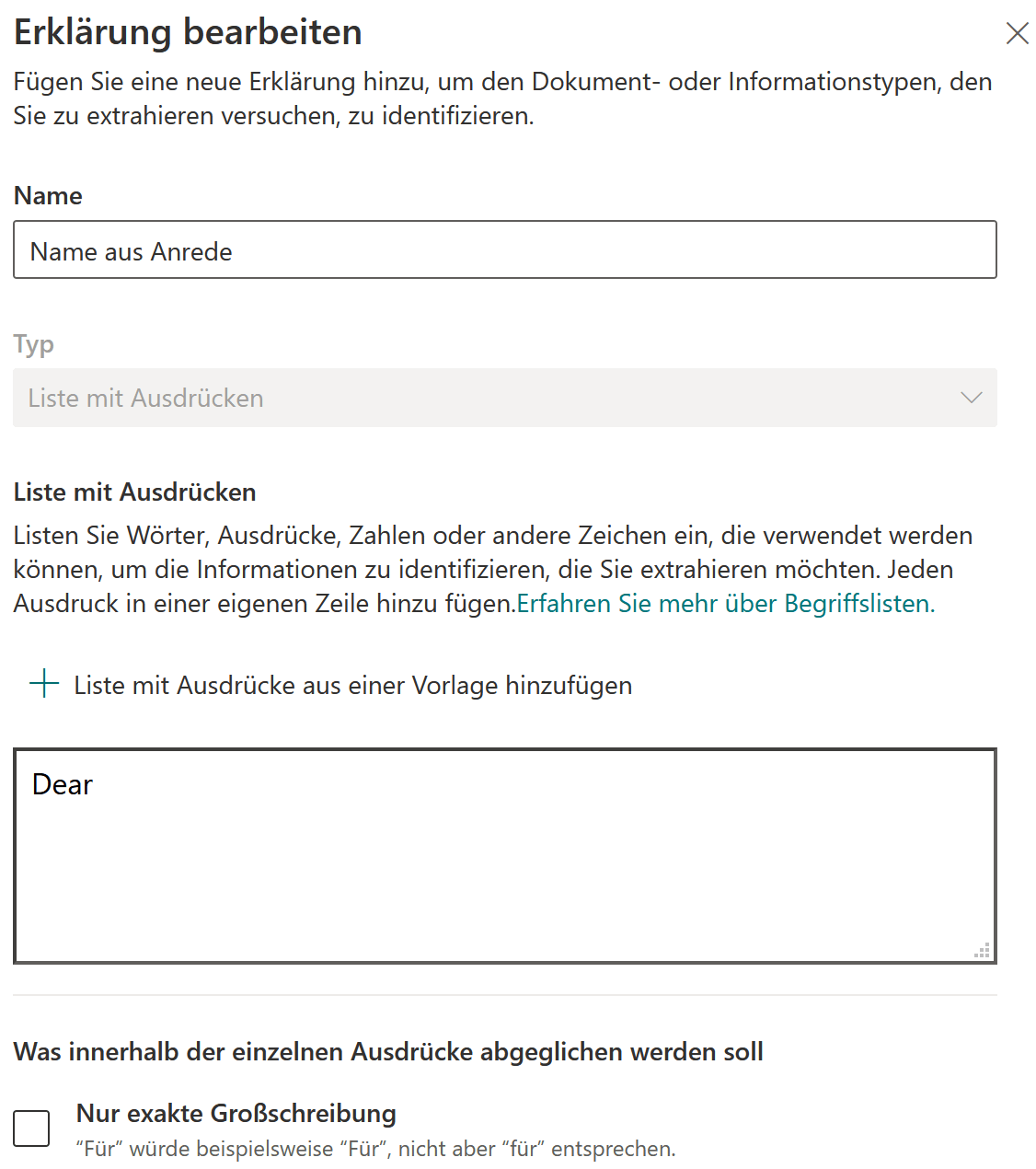
In einem weiteren Schritt muss nun der zu übernehmende Wert identifiziert werden, dieser kann ja theoretisch irgendwo im Dokument stehen oder Werte können auch mehrmals vorkommen. Durch Regeln oder Begriffe kann der Wert entsprechend identifiziert werden. Nach dem Speichern der Regel wird diese automatisch auf die Übungsdokumente angewendet und auch wieder mit einem Genauigkeitswert in Prozent die Erfolgsquote angegeben, welche im Besten Fall auch wieder bei 100% liegt.
Schritt 6: Syntex auf SharePoint Bibliotheken anwenden
Syntex wurde nun auf die Klassifizierung sowie das Extrahieren von Informationen trainiert. Über die entsprechende Aktion kann das erstellte Modell nun auf Dokumenten-Bibliotheken angewendet werden, dabei kann die entsprechende Site gesucht und die gewünschte Bibliothek markiert werden, auf die das Modell angewendet werden soll. Dabei werden die Inhaltstypen, wie auch die Spalten auf die Bibliothek übernommen.
Wechselt man dann auf die entsprechende Bibliothek, wird das Model auf alle bestehenden Dokumente angewendet und alle Dokumente nacheinander durchgearbeitet und die konfigurierten Informationen ausgefüllt. Syntex kann auch manuell auf Dokumente angewendet werden.

Integration von weiteren Microsoft 365 Services in SharePoint Syntex
Beim Erstellen von Klassifizierungen und dem Extrahieren von Informationen können in Syntex auf die bestehende Content Services «Managed Metadaten» sowie «Inhaltstyp-Galerie» zurückgegriffen werden. Diese können eingesetzt werden, dass Tenant-weit die gleichen Inhaltstypen und Spalten genutzt werden – also diese zentral verwaltet werden und nicht dezentral an verschiedenen Orten gepflegt werden müssen.
Im Weiteren kann auf Power Automate zurückgegriffen werden. So können Dokumenten mit Syntex in einer zentralen Bibliothek klassifiziert werden, mit Power Automate können anschliessend die Dokumente aufgrund ihrer Klassifizierung oder natürlich auch aufgrund von Werten, bspw. an einen anderen Speicherort verschoben werden.
Vordefinierte Rententionlabels im Security & Compliance Center können in den Modellen hinterlegt werden, diese werden dann auf die Dokumente angewendet, welche für die Klassifizierung identifiziert wurden.
Wie wird Syntex lizenziert?
SharePoint Syntex wird pro Benutzer/Monat als Add-On lizenziert. Voraussetzung ist eine E3- oder E5-Lizenz. Die Lizenz muss dem entsprechenden Benutzer oder der Benutzerin zugewiesen werden, damit Syntex für den User verfügbar ist und die Modelle erstellt, konfiguriert und trainiert werden können.
Bei der Nutzung des Form Process Model sind zusätzliche AI-Builder Credits notwendig.
Wie lautet das Fazit der IOZ AG?
SharePoint Syntex bietet einen einfachen Einstieg in das Thema der künstlichen Intelligenz. Es wird bewusst aufgezeigt, wie die künstliche Intelligenz im Büroalltag genutzt werden kann und diese nun stetig Einzug halten wird. Repetitive, manuelle Arbeiten können in Zukunft einfach automatisiert werden, dadurch kann auf die wesentliche Arbeit fokussiert werden. Mit der automatischen Klassifizierung und dem Extrahieren von Informationen von Dokumenten wird die Digitalisierung weiter voranschreiten und wohl so einige Papierarchive ablösen und durchsuchbar machen.
Und nicht vergessen, es handelt sich um Machine Teaching, Syntex hat nie ausgelernt und ist wissenshungrig. Am besten mit konkreten, hilfreichen UseCases starten bei denen auch der Nutzen für die Automatisierung zu erkennen ist – so kann Syntex zu Höchstleistungen trainiert werden!
Wie sieht die Syntex Roadmap aus?
Laut Microsoft stellt SharePoint Syntex nur einen ersten Schritt in Richtung der Project Cortex-Vision dar. Im Jahr 2021 sind einige Erweiterungen vom Project Cortex und Weiterentwicklungen von Syntex angekündigt.
- Themen Seiten und Cards werden in SharePoint und über M365 implementiert
- Automatische Erkennung von Themen
- Erweiterung der Modell-Typen und zentrales Modell Management
- Unternehmens-Metadaten (Taxonomie) Verbesserung über M365 hinweg
- Vernetzung von Themen, Expertise und Metadaten
Weiter werden bestimmt immer wieder dazu kommen.





Pingback: Productivity News vom 01.02.2021: SharePoint Syntex